Publications
publications by categories in reversed chronological order. generated by jekyll-scholar.
2025
-
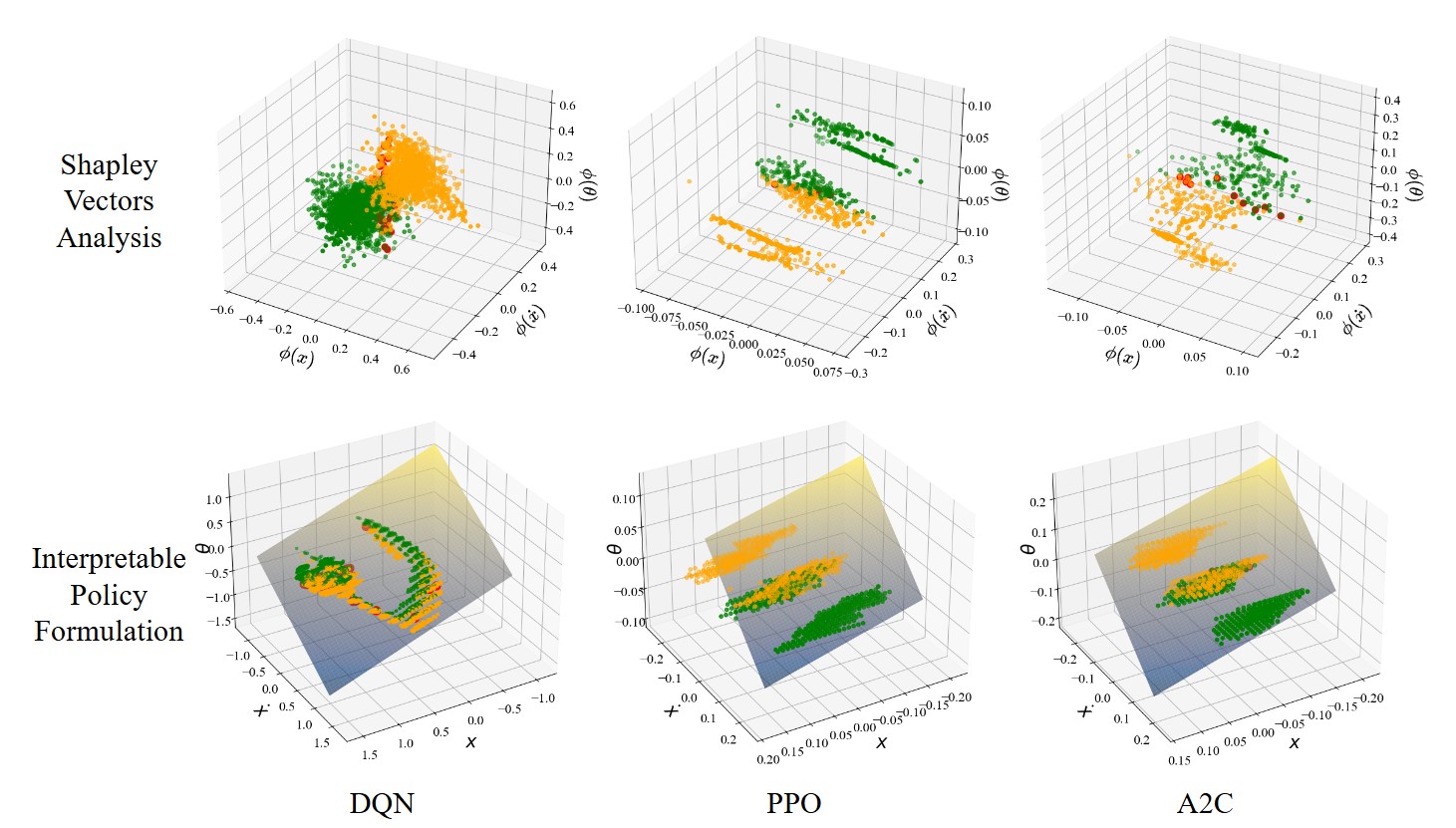 From Explainability to Interpretability: Interpretable Policies in Reinforcement Learning Via Model ExplanationPeilang Li, Umer Siddique, and Yongcan Cao2025
From Explainability to Interpretability: Interpretable Policies in Reinforcement Learning Via Model ExplanationPeilang Li, Umer Siddique, and Yongcan Cao2025Deep reinforcement learning (RL) has shown remarkable success in complex domains, however, the inherent black box nature of deep neural network policies raises significant challenges in understanding and trusting the decision-making processes. While existing explainable RL methods provide local insights, they fail to deliver a global understanding of the model, particularly in high-stakes applications. To overcome this limitation, we propose a novel model-agnostic approach that bridges the gap between explainability and interpretability by leveraging Shapley values to transform complex deep RL policies into transparent representations. The proposed approach offers two key contributions: a novel approach employing Shapley values to policy interpretation beyond local explanations and a general framework applicable to off-policy and on-policy algorithms. We evaluate our approach with three existing deep RL algorithms and validate its performance in two classic control environments. The results demonstrate that our approach not only preserves the original models’ performance but also generates more stable interpretable policies.
@misc{li2025explainabilityinterpretabilityinterpretablepolicies, title = {From Explainability to Interpretability: Interpretable Policies in Reinforcement Learning Via Model Explanation}, author = {Li, Peilang and Siddique, Umer and Cao, Yongcan}, year = {2025}, eprint = {2501.09858}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, url = {https://arxiv.org/abs/2501.09858}, } -
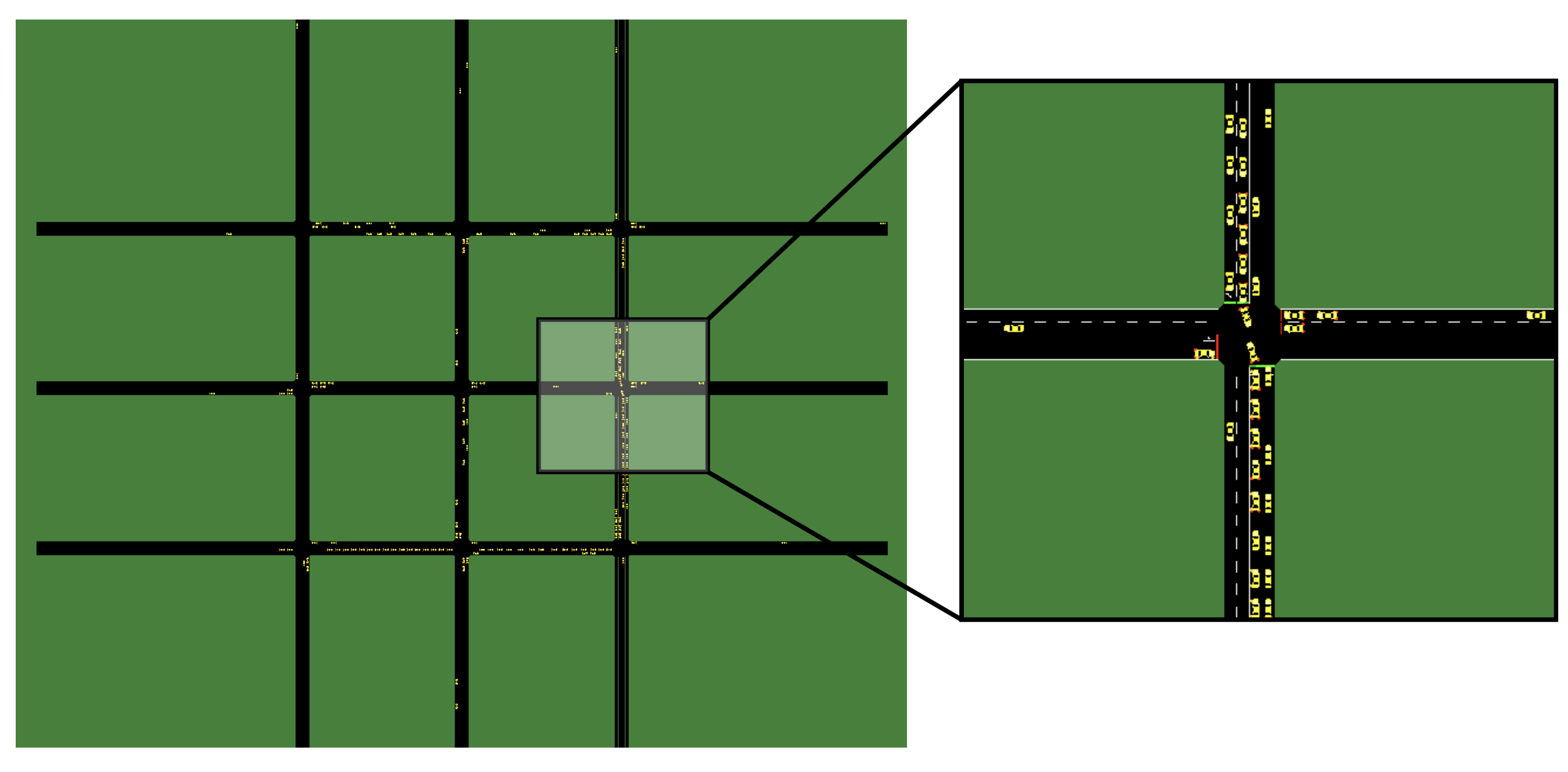 Fairness in Traffic Control: Decentralized Multi-agent Reinforcement Learning with Generalized Gini Welfare FunctionsUmer Siddique, Peilang Li, and Yongcan CaoIn Multi-Agent reinforcement Learning for Transportation Autonomy, 2025
Fairness in Traffic Control: Decentralized Multi-agent Reinforcement Learning with Generalized Gini Welfare FunctionsUmer Siddique, Peilang Li, and Yongcan CaoIn Multi-Agent reinforcement Learning for Transportation Autonomy, 2025In this paper, we address the issue of learning fair policies in decentralized cooperative multi-agent reinforcement learning (MARL), with a focus on traffic light control systems. We show that standard MARL algorithms that optimize the expected rewards often lead to unfair treatment across different intersections. To overcome this limitation, we design control policies that optimize a generalized Gini welfare function that explicitly encodes two aspects of fairness: efficiency and equity. Specifically, we propose three novel adaptations of MARL baselines that enable agents to learn decentralized fair policies, where each agent estimates its local value function while contributing to welfare optimization. We validate our approaches through extensive experiments across six traffic control environments with varying complexities and traffic layouts. The results demonstrate that our proposed methods consistently outperform existing MARL approaches both in terms of efficiency and equity.
@inproceedings{siddiquefairness, title = {Fairness in Traffic Control: Decentralized Multi-agent Reinforcement Learning with Generalized Gini Welfare Functions}, author = {Siddique, Umer and Li, Peilang and Cao, Yongcan}, booktitle = {Multi-Agent reinforcement Learning for Transportation Autonomy}, year = {2025}, } -
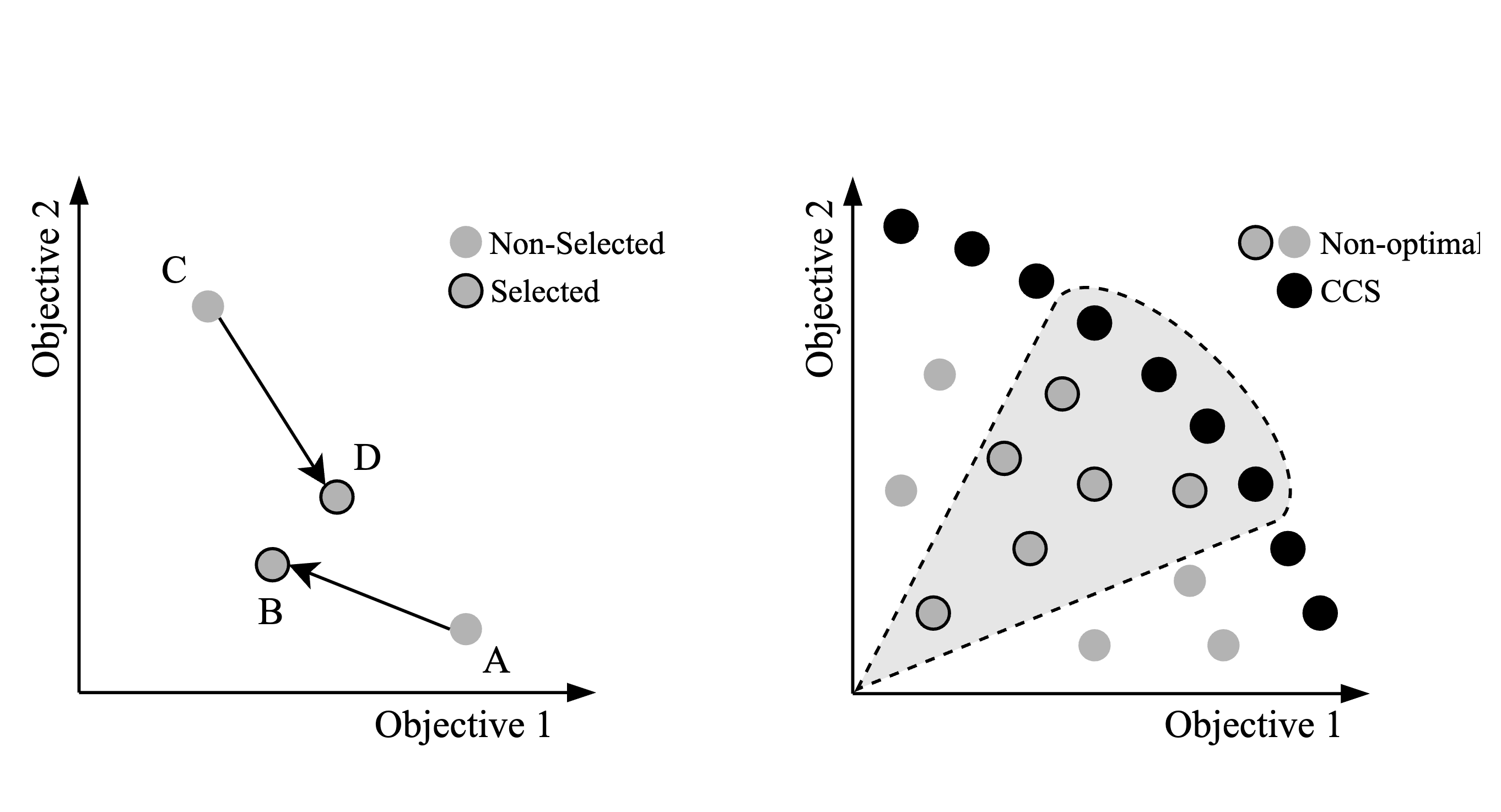 Learning Fair Pareto-Optimal Policies in Multi-Objective Reinforcement LearningUmer Siddique, Peilang Li, and Yongcan CaoIn The Seventeenth Workshop on Adaptive and Learning Agents, 2025
Learning Fair Pareto-Optimal Policies in Multi-Objective Reinforcement LearningUmer Siddique, Peilang Li, and Yongcan CaoIn The Seventeenth Workshop on Adaptive and Learning Agents, 2025Fairness is an important aspect of decision-making in multi-objective reinforcement learning (MORL), where policies must ensure both optimality and equity across multiple, potentially conflicting objectives. While \emphsingle-policy MORL methods can learn fair policies for fixed user preferences using welfare functions such as the \emphgeneralized Gini welfare function (GGF), they fail to provide the diverse set of policies necessary for dynamic or unknown user preferences. To address this limitation, we formalize the fair optimization problem in \textitmulti-policy MORL, where the goal is to learn a set of Pareto-optimal policies that ensure fairness across all possible user preferences. Our key technical contributions are threefold: (1) We show that for concave, piecewise-linear welfare functions (e.g., GGF), fair policies remain in the \emphconvex coverage set (CCS), which is an approximated Pareto front for linear scalarization. (2) We demonstrate that non-stationary policies, augmented with accrued reward histories, and stochastic policies improve fairness by dynamically adapting to historical inequities. (3) We propose three novel algorithms, which include integrating GGF with multi-policy multi-objective Q-Learning (MOQL), state-augmented multi-policy MOQL for learning non-statoinary policies, and its novel extension for learning stochastic policies. To validate the performance of the proposed algorithms, we perform experiments in various domains and compare our methods against the state-of-the-art MORL baselines. The empirical results show that our methods learn a set of fair policies that accommodate different user preferences.
@inproceedings{siddiquelearning, title = {Learning Fair Pareto-Optimal Policies in Multi-Objective Reinforcement Learning}, author = {Siddique, Umer and Li, Peilang and Cao, Yongcan}, booktitle = {The Seventeenth Workshop on Adaptive and Learning Agents}, year = {2025}, }



2024
-
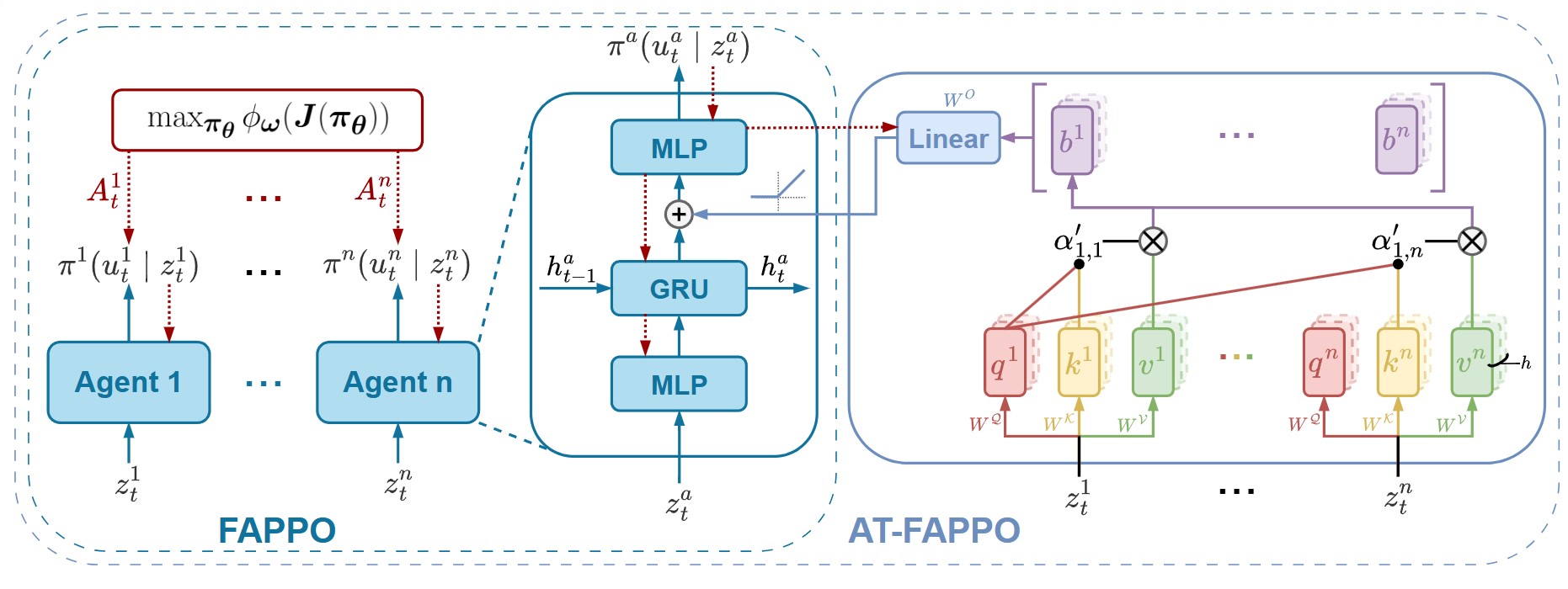 Towards Fair and Equitable Policy Learning in Cooperative Multi-Agent Reinforcement LearningUmer Siddique, Peilang Li, and Yongcan CaoIn Coordination and Cooperation for Multi-Agent Reinforcement Learning Methods Workshop, 2024
Towards Fair and Equitable Policy Learning in Cooperative Multi-Agent Reinforcement LearningUmer Siddique, Peilang Li, and Yongcan CaoIn Coordination and Cooperation for Multi-Agent Reinforcement Learning Methods Workshop, 2024In this paper, we consider the problem of learning independent fair policies in cooperative multi-agent reinforcement learning (MARL). The objective is to design multiple policies simultaneously that can optimize a welfare function for fairness. To achieve this objective, we propose a novel Fairness-Aware multi-agent Proximal Policy Optimization (FAPPO) algorithm, which learns individual policies for all agents separately and optimizes a welfare function to ensure fairness among them, in contrast to optimizing the discounted rewards. The proposed approach is shown to learn fair policies in the independent learning setting, where each agent estimates its local value function. When inter-agent communication is allowed, we further introduce an attention-based variant of FAPPO (AT-FAPPO) by incorporating a self-attention mechanism for inter-agent communication. This variant enables agents to communicate and coordinate their actions, potentially leading to more fair solutions by leveraging the ability to share relevant information during training. To show the effectiveness of the proposed methods, we conduct experiments in two environments and show that our approach outperforms previous methods both in terms of efficiency and equity.
@inproceedings{siddiquetowards, title = {Towards Fair and Equitable Policy Learning in Cooperative Multi-Agent Reinforcement Learning}, author = {Siddique, Umer and Li, Peilang and Cao, Yongcan}, booktitle = {Coordination and Cooperation for Multi-Agent Reinforcement Learning Methods Workshop}, year = {2024}, }
